|
4. STEPlib乛RDL徻嵶
4.1.1.1 堦斒揑側僨乕僞儌僨儕儞僌庤朄偵偮偄偰
丂崱擔堦斒偵峴傢傟偰偄傞僨乕僞儌僨儕儞僌偺庤朄偼丄乭僄儞僥傿僥傿宆乭乮乭僆僽僕僃僋僩宆乭偲偄偭偰傕傛偄乯偲偦傟傜偵娭學偡傞乭懏惈宆乭暲傃偵僄儞僥傿僥傿宆憡屳偺娭學傪嬱巊偟偨傕偺偱偁傞丅偙傟傜偺娭學偼摿暿偺懏惈宆偱昞尰偝傟偰偄偰丄乭foreign
key乭偲屇偽傟偰偄傞丅僆僽僕僃僋僩巜岦偵傛傞儌僨儕儞僌偱偼丄婔偮偐偺晅壛揑側奣擮偑巊傢傟偰丄偦偺堦偮偵乭儊僜僢僪乭偑偁傝僆僽僕僃僋僩偺價僿僀價傾乕傪僀儀儞僩偲僒僽僞僀僾傪梡偄偰婰弎偡傞丅偙偙偵僒僽僞僀僾偲偼丄僆僽僕僃僋僩宆偺娫偱僗乕僷乕乛僒僽偺娭學傪掕媊偡傞傕偺偱偦偺懏惈傗價僿僀價傾乕傪壓埵偺僆僽僕僃僋僩宆乮巕僆僽僕僃僋僩乯偵忋埵偺宆乮恊僆僽僕僃僋僩乯偐傜宲彸傪掕媊偡傞傕偺偱偁傞丅
丂偙偺庤朄偺傕偆堦偮偺婎杮揑側傕偺偼丄乭僀儞僗僞儞僗乭偱偁傞丅僀儞僗僞儞僗偲偼僨乕僞儀乕僗偺棙梡幰偵傛偭偰擖椡偝傟傞傕偺偱丄懏惈宆偺僀儞僗僞儞僗偲偟偰曐懚偝傟丄僀儞僗僞儞僗偲偄偆僄儞僥傿僥傿宆偵僌儖乕僺儞僌偝傟傞傕偺偱偁傞丅
丂偙傟傜偺奣擮偼丄IT偺愱栧壠乮僨乕僞儌僨儕儞僌壠乯偵傛偭偰梡偄傜傟丄乭僨乕僞儌僨儖乭偲偟偰婰壇偝傟僨乕僞儀乕僗偺峔憿傪寛掕偡傞丅偦偺僨乕僞儌僨儖偼丄幚僨乕僞傪夝庍偡傞偨傔偺僙儅儞僥傿僋僗傪掕媊偟丄棙梡幰偑懏惈偺僀儞僗僞儞僗傪曐懚偡傞偺偵嫙偡傞丅
丂
4.1.1.2 尰嵼峴傢傟偰偄傞庤朄偺栤戣揰
丂崱擔堦斒揑偵側偭偰偄傞僨乕僞儌僨儕儞僌偵嫟捠偟偨摿挜偼丄僨乕僞儌僨儖偺掕媊偑2偮偵柧妋偐偮嫮屌偵暘偗傜傟偰偄傞偙偲偱丄堦偮偼僨乕僞峔憿偱僙儅儞僥傿僋僗傗儐乕僓僨乕僞偺堄枴傪掕媊偟偰偄傞丅傕偆堦偮偼儐乕僓僨乕僞偱偁傞丅偦偺寢壥偲偟偰丄偙偺庤朄偱偼丄僙儅儞僥傿僋僗儖乕儖偺掕媊偵偼丄堦斒偺僨乕僞儀乕僗偺傾僾儕働乕僔儑儞棙梡幰偺棫応偱偼傾僋僙僗偱偒側偄偟奼挘傕偱偒偢丄捠忢偼乭儐乕僓僀儞僞乕僼僃僀僗乭傪梡偄傞偙偲偱塀暳偝傟偰偄傞丅偙偺堊偵摑崌傗偍屳偄偺僔僫僕乕岠壥偑敪婗偱偒偰側偄丅偙偺偙偲偼丄恖娫偺堦斒揑側僐儈儏僯働乕僔儑儞偲戝偒偔堎側偭偰偄傞偲偄偊傞丅偲偄偆偺傕岎姺僨乕僞偑昞尰偝傟偰偄傞偺偲摨偠尵岅偱丄夝庍偺儖乕儖傪採嫙偡傞偙偲偑弌棃傞偐傜偱偁傞丅
拲丗 |
|
偙偺擇幰娫偺妘偨傝偑摉偨傝慜偺傕偺偲側偭偰偄偰丄僄儞僥傿僥傿宆偲懏惈宆偑屌掕偝傟偨柤慜傪帩偮偺偩偑丄偙傟偼晛捠偺巇帠偱憳嬾偡傞僆僽僕僃僋僩宆偺柤慜偲偼柧傜偐偵堎側偭偰偄傞丅偙偺IT儌僨儖偲儐乕僓僨乕僞娫偱堎側偭偰偄傞偲偄偆偙偲偑丄偝傜偵僀儞僥僌儗乕僔儑儞偺忈暻偵傕側偭偰偄傞丅
|
丂傑偨崱擔偺庤朄偺暿偺惂栺偲偟偰丄堦扷僨乕僞儀乕僗偺愝掕偑廔椆偡傞偲丄偦偺僨乕僞儌僨儖偑屌掕偝傟丄儐乕僓僨乕僞傪夝庍偡傞僙儅儞僥傿僋僗偑屌掕偝傟偰偟傑偆偙偲偑偁傞丅偙偺僙儅儞僥傿僋僗傪奼挘偡傞偵偼丄僨乕僞儀乕僗偺峔憿傪嵞掕媊偟偰丄屆偄僨乕僞傪怴偟偄傕偺偵堏偟偰傗傜側偗傟偽側傜側偄丅
丂崱偺庤朄偵懳偡傞傕偆堦偮偺惂栺偼丄僨乕僞儌僨儖偺僗僐乕僾偑惂尷偝傟偰偄偰傕丄偁傞偄偼僨乕僞儌僨儖偑戝偒偔側偭偨傝丄偁傞偄偼斈梡揑偵側偭偰傕丄偦傟傪偄偠傞偙偲偑梕堈偱偼側偄丅僨乕僞儌僨儖偺斈梡壔偼僙儅儞僥傿僢僋偺妋偐偝傪幐偆偙偲偵偮側偑傞丅
丂嵟屻偵丄僨乕僞儌僨儖偼丄偦傟偧傟堎側偭偰偄偰丄堎側傞僔僗僥儉娫偺僨乕僞岎姺偼丄摿掕偺僨乕僞峔憿枅偵峴傢傟側偗傟偽側傜側偄偙偲偱偁傞丅偙傟偼崱擔偺僨乕僞儌僨儕儞僌庤朄偑丄僔僗僥儅僥傿僢僋偱偼側偔丄婛懚偺傕偺傪嵞棙梡偡傞堊偺昗弨壔偝傟偨傾僾儘乕僠偱偼側偄偙偲傪堄枴偡傞丅
丂
丂杮曬偱偼丄偙偆偄偭偨儐乕僓僨乕僞偲IT儌僨儖僨乕僞偺娫偱惂栺傗忈暻傪帩偨側偄曽朄榑傪娙寜偵徯夘偡傞丅斀柺丄偦傟偼戲嶳偺奼挘壜擻側僙儅儞僥傿僋僗傪掕媊偡傞傕偺偱丄僨乕僞儀乕僗偦偺傕偺偵曐懚偝傟20,000僄儞僥傿僥傿偲偦傟偵娭學偡傞懏惈偐傜側傞僨乕僞儌僨儖偵摍偟偄丅
丂僙儅儞僥傿僋僗偺廮擃惈偼丄師偺帠暱偵傛偭偰払惉偝傟傞丟
1. 僋儔僗乮type of things乯偵娭偡傞抦幆偲屄暿偺僆僽僕僃僋僩偺抦幆偺椉幰傪摨偠僨乕僞儀乕僗偵曐懚偱偒傞
2. 懏惈宆偲僀儞僗僞儞僗偲偺娫偺張棟偺憡堘偑敪惗偟側偄丄懏惈宆傪僋儔僗偲偟偰僀儞僗僞儞僗偲懳偱僨乕僞儀乕僗偵曐懚偟偰偄偰丄僀儞僗僞儞僗傪屄暿偺懏惈抣乮僀儞僗僞儞僗乯偲奩摉偡傞僋儔僗娫偺柧帵揑側僋儔僗偺娭學偱抲姺偊偰偄傞丅
3. 僄儞僥傿僥傿宆偲懏惈宆偺娫偺憡堘傪側偔偟偰丄僄儞僥傿僥傿偲偦偺懏惈偲偺娫偺埫栙偺娭學傪僀儞僗僞儞僗娫偺柧帵揑側乫possession of aspect乫娭學偱抲偒姺偊偰偄傞丅
恾8偼堦斒揑側庤朄偲杮曬偱弎傋傞Gellish庤朄偲偺杮幙揑側奣擮傪斾妑偟偰偄傞丅
丂
(EXPRESS) Data Model Concepts |
(AP221) Gellish Data Base Concepts |
1. |
Instantiation
-Implicit classification relations |
1. |
Explicit classification relations |
2. |
Entities have Attributes
-Implicit relations between entity and attributes
-Implicit roles of objects in relations |
2. |
Explicit Relations between objects
Explicit roles of objects in relations |
3. |
Subtyping of entities (not of attributes)
-Methodology does not require a consistent subtyping strategy
-Usually a limited use of inheritance |
3. |
Specialization relations between classes
-Methodology requires that every class has at least one supertype, which results in one big specialization hierarchy
-Full use of inheritance |
4. |
Entity and attribute types are not instances (fixed data model)
-Fixed knowledge model outside database |
4. |
Entity types and attribute types (classes) are instances
-Flexible knowledge model in database |
恾8 Comparison of EXPRESS concepts with Gellish concepts
丂
丂傾僾儕働乕僔儑儞偵Gellish Methodology傪揔梡偡傞偲丄僨乕僞儌僨儖偼廮擃惈偵晉傒奼挘惈傕帩偮偙偲偑偱偒傞丄偦傟偼儐乕僓偺knowledge傪曐懚偡傞傕偺偱丄儐乕僓偵偼儊僞側儌僨儖偵尒偊傞丅
丂Library偵掕媊偝傟偰偄傞STEPlib偲Gellish尵岅偼丄偙偺Methodology傪幚憰偟偨傕偺偱偁傞丅堦曽STEPlib
Browser偼傾僾儕働乕僔儑儞僜僼僩僂僃傾偱丄knowledge傗屄乆偺僆僽僕僃僋僩傪價儏乕僀儞僌偡傞傕偺偱丄偙偺Methodology偺慺惏傜偟偝傪懱尡偱偒傞傕偺偱偁傞丅
丂傛傝徻偟偄忣曬偵偮偄偰偼丄師偺傕偺傪嶲徠偝傟偨偄丟
亅Gellish on the Web, a short introduction of the capabilities of Gellish to express messages.
亅Guide on STEPlib, a guide to extent STEPlib and the
Gellish language
亅The Gellish Reference Manual, a Gellish user guide
亅The STEPlib database, a set of tables (in EXCEL) or a CLB database file native to the STEPlib Browser.
亅The STEPlib Browser
丂
丂偙偺僷儔僌儔僼偱偼丄僨乕僞偲僙儅儞僥傿僋僗偺曐懚偵偮偄偰丄捠忢偺応崌偲Gellish偺応崌偵偮偄偰斾傋偰傒傞丅
丂師偺椺偵偰愢柧偡傞偲丟
亅偁傞億儞僾乮乪P-1乫乯偑丄偁傞棳懱乮乪S-1乫乯傪媯傒忋偘偰偄傞偲偡傞丅
丂捠忢偺僨乕僞儀乕僗偱偼丄暔偺夝庍傪偡傞僙儅儞僥傿僋僗傪掕媊偡傞堊偵丄僨乕僞儌僨儖偲偟偰婔偮偐偺僄儞僥傿僥傿宆偲懏惈宆傪掕媊偟側偗傟偽側傜側偄丅偙偺椺偱偼丄僨乕僞儌僨儖偼丄僄儞僥傿僥傿宆偲偟偰丄乪pump乫丄乪process乫傗乪stream乫媦傃偦傟偧傟偺懏惈偑掕媊偝傟傞丅
丂Gellish偱偼丄乪pump乫丄乪process乫傗乪stream乫偺奣擮偼僄儞僥傿僥傿宆偱偼側偔丄僀儞僗僞儞僗偺娭學偵傛偭偰斈梡揑側僨乕僞儀乕僗偵掕媊偝傟傞傕偺偱丄嵟掅尷偺悢偺乪basic
semantic axioms乫偺傒傪抦傞偩偗側偺偱偁傞丅傑偨僨乕僞儀乕僗偵偼戲嶳偺晅壛揑側帠暱傪傆偔傫偱偄傞丅嵟掅尷偺悢偺乪basic semantic
axioms乫偼丄梊傔暘偐偭偰偄側偗傟偽偄偗側偄偟丄偐偮晅壛揑側僙儅儞僥傿僋僗側帠暱傪掕媊偡傞偵廫暘側傕偺偱側偗傟偽側傜側偄丅
丂怴偟偄帠暱傪掕媊偡傞偵偼丄悢乆偺弶曕揑側帠傪丄怴偟偄帠暱偲婛懚偺帠暱偲偺娫偺娭學傪昞尰偟偰掕媊偡傞昁梫偑偁傞丅暿偺尵偄曽傪偡傞側傜丄怴婯偺帠暱偼恾9偵帵偡峔憿傪嶌傞昁梫偑偁傞丅
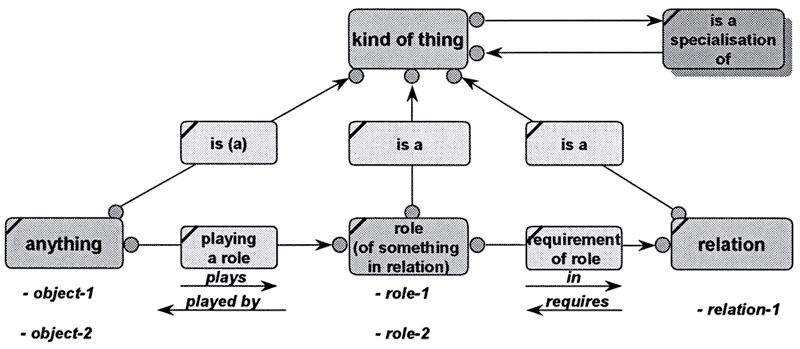
丂怱摼偰偍偔昁梫偑偁傞嵟掅尷偺悢偺乪basic semantic axioms乫偲偼丟
亅anything
亅role
亅relation乛relations
亅plays role
亅requires role
亅is乛is a (is classified as a)
亅specialization of kind (is a specialization of)
亅individual thing乛individual things
亅kind of thing乛kind of things
亅single thing乛plural thing
丂偙偺嵟掅僙僢僩偼恾9偵帵偝傟偰偄傞丅
丂
| 乮奼戝夋柺丗36KB乯 |
|
恾9 Basic semantic axioms
丂
丂2偮傑偨偼偦傟埲忋偺乪僆僽僕僃僋僩乫娫偺乪atomic relation乫偵傛偭偰丄乪僆僽僕僃僋僩乫偲乪role乫偲乪relation乫偺僋儔僗暘偗偵傛偭偰丄怴偟偄乪atomic
fact乫偑昞尰偝傟傞丅偙傟偼丄怴偟偄atomic fact偼丄恾9偺惵偄敔偱昞傢偝傟偨9働偺relation乮5働拞4働偺敔偼2偮偺relation傪帩偮乯偵傛偭偰昞傢偝傟傞偲偄偆偙偲傪堄枴偡傞丅僙儅儞僥傿僢僋傪奼挘偡傞怴偟偄fact偼丄乪僆僽僕僃僋僩乫娫偺relation偵傛偭偰昞尰偝傟傞丄偦偺僆僽僕僃僋僩偲偼kind
of things偱偁傞丅
丂椺偲偟偰丄僀儞儁儔乕O1偑塓姫億儞僾O2偺part偱偁傞乮impeller O1 is part of centrifugal pump O2乯応崌傪丄Gellish偱師偺4働偺弶曕揑側娭學偱昞傢偡丟
亅object O1 plays role R1
亅role R1 is required by relation C1
亅relation C1 requires role R2
亅role R2 is played by object O2
師偺5働偺晅壛僋儔僗偺relation偑偁傞丟
亅O1 is classified as an 'impeller'
亅R1 is classified as a 'part'
亅C1 is classified as a 'part-whole relation'
亅R2 is classified as a 'whole'
亅O2 is classified as a 'centrifugal pump'
丂幚嵺偵幚憰偡傞偵偼丄Role偲僋儔僗偵懳偡傞柧帵揑側幆暿巕偼柍帇偝傟傞丅壗屘側傜relation偺僋儔僗偱榙傢傟傞偐傜偱偁傞丅
丂廬偭偰丄忋婰偺娭學偼丄捠忢偮偓偺3働偺Gellish偵廤栺偝傟傞丟
亅O1 is classified as an 'impeller'
亅O1 is part of O2
亅O2 is classified as a 'centrifugal pump'
丂
丂偙偺椺偲偟偰丄5働偺僋儔僗暘偗偝傟偨kind of things偑丄偙傟偑掕媊偝傟傞埲慜偵丄掕媊偝傟偰偄側偗傟偽側傜側偄丅偙傟偼丄STEPlib儔僀僽儔儕偱巊偊傞傛偆偵Gellish僨乕僞儀乕僗偺僩僢僾僟僂儞奒憌掕媊傪惗傓偙偲偵偁傞丅
丂堦椺偲偟偰丄乪centrifugal pump乫偲偄偆掕媊偼丄暘偐偭偰偄傞昁梫偑偁傞丅偙偺峫偊偼2働偺娭學偱掕媊偝傟傞丟
亅埲壓偺掕媊傪峴偆relation偺摿庩壔乮specialization乯丟
'centrifugal pump乫偼乪pump乫偺僒僽僞僀僾偱偁傞
亅Centrifugal pump傪掕媊偡傞偵偼丄centrifugal偺尨懃傪梡偄傞
'centrifugal pump乫偼乪centrifugal乫偲掕媊偝傟傞
丂憃曽偺娭學偼丄乪pump乫偲乪centrifugal乫偵娭偡傞埲崀偺徻嵶側掕媊偵棫媟偟偰嶌傜傟傞丅
丂恾2偺奺乆偺敔偼丄扨悢偺thing傑偨偼暋悢偺thing偲偟偰夝庍偝傟傞偙偲偵拲堄偺偙偲丅椺偊偽丄傕偟乪anything乫偑暋悢偺傕偺偵懳偡傞億僀儞僞乕偱偁傟偽丄偦偺僋儔僗偺娭學偼暋悢偺奺梫慺枅偺僋儔僗偵側傞丅偝傜偵丄乪kind of thing乫偼丄3働偺僋儔僗偵懳偟偰kind of anything丄偮傑傝kind of role偲kind of relation傪偦傟偧傟昞傢偡偺偱丄乪kind of things乫偵側傞丅
|