XMLで記述される文書は、図2のように分かり易く単純です。まず、XML文にあらわれるデータ要素または構造化されたデータ要素群は、開始タグ(例.<name>)と終了タグ(例.</name>)で囲まれて定義されます。すなわち、この例では<name>タグで名づけられたデータ内容が日本株式会社であることを示しています。また、<contact>タグで囲まれた連絡先情報は、<person>と<email>から構成されることも表しています。もし、これらのタグを予め定義し、情報交換を行う当事者間でその意味を共通理解できるのであれば、XML文書で記述された情報は企業間アプリケーション同士で自動処理できるはずです。この予め定義したタグ情報を規定するのがデータ型定義文(DTD: Data Type Definition)です。(XML構文についての詳しい説明は本書の付録を参照。)
ところで、図2で定義してある<name>タグは何を意味しているのでしょうか。もちろん人が見たら、どうも取引先の企業名らしいと分かります。しかしながら、コンピュータ・アプリケーションでは、タグの<name>だけを判別して、自分のアプリケーションが扱うファイルの<name>対応欄に格納します。もし、アプリケーションが扱う<name>対応欄が連絡先人名として扱う情報欄であると、このXML文で送られてきた情報は違った意味で解釈され、送り手が期待した処理とは異なったことが行われるかも知れません。すなわち、XML構文が提供している機能は、タグ付けによるデータ要素の識別とその構文構造だけで、けっして意味情報の定義機能を提供してはいません。それぞれのタグの持つ意味は、企業間で別途に取り決める必要があります。広い範囲で自由にXML文を交換し、それぞれでアプリケーションを実行させられる環境にするためには、タグの意味情報を標準として厳密に定義した電子的な公開辞書、すなわちリポジトリが必要となります。
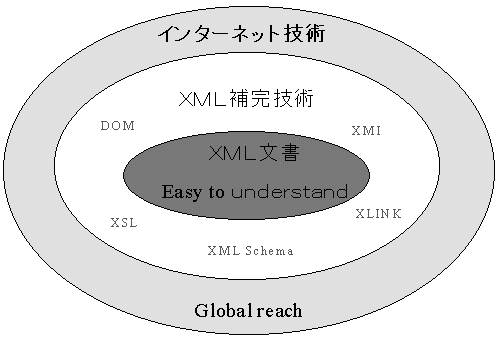
さて、XML構文規則は既に説明したように、タグ付けしたデータ要素とその情報構造を定義する文法です。よって、XML文をインターネット環境で交換し、また異なるアプリケーション間での処理に繋げるためには、さらにXML文を取り扱う幾多の補完技術が必要となります。