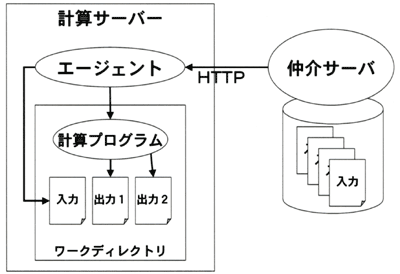
|
図3-3
仲介サーバは、以下の機能要素から構成した。
1)ウェブサーバ
2)ブラウザに対するCGI
3)エージェントに対するCGI
4)リレーショナルデータベース
5)ファイルレポジトリ
エージェントは、以下の機能要素から構成した。
1)HTTPクライアント
2)計算プログラム起動・制御
3)ファイルダウンロード/アップロード
4)GUI
エージェントについては、仲介サーバからメンバーが自由にダウンロードして各自の計算機にインストールできるようにした。ユーザの利便性を考えて、インストーラプログラムとして提供した。エージェントの稼働環境は、LinuxとWindowsである。
エージェントのインストールにあたっては、エージェントの挙動を制御するパラメータを各自の計算機のネットワーク環境、計算プログラムにあわせて設定する。計算エージェントの挙動を制御するパラメータは以下のとおりである。
リソースに関する指定
同時に実行可能な計算プロセス数
タスクレポジトリサーバへの問い合わせの時間間隔
計算プログラムに関する指定
計算プログラムの名前
計算プログラムのバージョン
計算プログラムの実行形式のファイルパス
計算プログラムを実行するためのワークディレクトリのベース
タスクレポジトリサーバに関する指定
サーバに接続する際のユーザ認証情報
HTTPプロキシーの設定
サーバのURL(CGI)
ブックマークの共有機能と全文検索機能を組み合わせたしくみを検索系と呼ぶ。検索系は、利用者アカウントごとにURLを登録・蓄積する機能と、登録されたURLについて、その指し示すページの内容を全文検索用のインデックスを作成する機能、このインデックスに基づいて検索を行う機能から構成する。これら機能は、サーバに集約して実現する。ユーザはこのサーバにウェブブラウザでアクセスするだけで利用することができる。
検索系は以下の機能から構成した。
1)URL登録
2)URLデータベース(リレーショナルデータベース)
3)ページコンテンツの取得
4)全文検索機能
URL登録機能は、ユーザ毎にURLリストを編集するユーザインターフェースである。ユーザは各自のURLリストを編集する。各ユーザのURLリストは、システム内部では統合される。
URLデータベースには、広く使われているPostgreSQLを使用した。
ページコンテンツの取得には、wgetを使用した。
全文検索機能は、全文検索システムとして広く使われているNamazuを使用した。
以上述べた検索系、計算系のサーバの運用を2003年11月に開始し、2004年3月まで実証実験を行った。登録ユーザ(参加者)は徐々に増加して、2004年3月時点での登録ユーザ数は約20名である。
検索系の運用状況について述べると、研究者個人個人からの登録だけでなく、4-4節で述べるように集中したグループ作業による検索系へのURL登録も行われ、情報ソースとしての価値が徐々に増してきた。その結果、4-3節の研究事例のように適切な情報を提供するウェブサイトを特定することができるようになってきている。
一方の計算系の運用状況については、計算系に接続された計算機は2003年2月13日に開催されたワークショップの時点で、下表のとおりである。
| CPU |
クロック
(GHz) |
メモリ
(MB) |
OS |
アプリ |
設置場所 |
| Pentium4 |
1.2 |
512 |
Linux |
CAMP-Atami
DeFT |
茨城県内 |
| Pentium4 |
2.66 |
512 |
Linux/VMware |
CAMP-Atami
Deft |
東京都千代田区内 |
| Pentium4 |
2.2 |
2048 |
Linux |
CAMP-Atami
DeFT |
川崎市内 |
| Xeon デュアル |
2 |
4096 |
Linux |
CAMP-Atami
DeFT |
川崎市内 |
| Celeron |
2 |
384 |
Linux/VMware |
CAMP-Atami
DeFT |
ワークショップ会場 |
|
以上のような運用の結果、開発した水科学プラットフォームが以下のような目的に適していることを確認した。
ある分野に特化した情報ソースを自発的に集積したい場合
研究者個人が開発したプログラムを公開したい場合
多数のケースを研究者同士が計算機を供出しあって計算する場合
水科学プラットフォームのサーバは今後も運用を続けて、水科学関連研究者のコミュニティの育成に役立てていく。
サーバのURLとゲストアカウントは以下のとおりである。
ユーザ名:water
パスワード:water
|