|
第3章 水科学プラットフォームプロトタイプの開発報告
3-1 全体機能・設計
2-3節で述べたように、一見非常に多彩な特性を示す水の統一的理解と水にかかわる既存知見を集約する活動を支えるITプラットフォームのプロトタイプを開発した。(以下、プラットフォーム)このプラットフォームは、産学の異なる組織に属する研究者が協働しあえる環境を提供する。具体的には、以下の2つの仕組みを提供する。
1)第1のしくみは、2章冒頭で述べたように研究者コミュニティの“共通言語”としてのシミュレーションソフトウェアに焦点を当てて、個々の研究者が開発あるいは整備したシミュレーションソフトウェア(以下、計算プログラム)の利用環境を相互に利用しあえるしくみ。以下、計算系と呼ぶ。
2)第2のしくみは、個々の研究者のURLブックマークを共有することによって、各人の検索体験の蓄積を統合し、水科学分野の研究にふさわしい情報に絞ったウェブサイトの検索を可能とするしくみ。以下、検索系と呼ぶ。
計算プログラムを自前で開発している個人あるいはグループの研究者は日本国内においても少なくはない、しかし開発者がそのプログラムを他の研究者に広く利用してもらいたいと思っても、プログラムそのものを配布することに躊躇するばあいが多い。第1のしくみである計算系は、プログラムを配布することなく他の研究者にプログラムを試用してもらうことをわずかな準備で可能とするものである。また、系統だった多数の計算を実行したい場合に研究者がお互いの計算機をネットワーク上で供出しあって効率的に計算を進めることを可能とする。
WWWと検索サービスによって研究に関わる様々な情報を共有できる環境が整ったが、一般の検索サービスでは、ある特定分野に関する質の高い情報に限って集めることはまだまだむずかしい。研究者個人個人がもつ経験と知識をうまくつなぎ合わせるための仕組みが必要である。本開発では、個人個人のもつ情報源が集約されているウェブブラウザのブックマークに着目し、ブックマークを共有することにより、興味の対象、情報ソースを共有し、研究者同士の知識の共有が実現できると考えた。ブックマークのURLを集めて共有し、かつそれら蓄積されたURLが示すぺージに対して全文検索をかけることができれば、特定分野ごとのURLリストを作成することによってその分野の情報源の集約を実現できる。
プラットフォームの設計にあたっては、以下の指針を策定した。
1)今回の開発がプロトタイプであり、実証実験で得られる知見を基に将来さまざまな改良を加えて発展させることが容易にできるように、可能な限りシンプルなシステムにすること。
2)研究者が手軽に参加できるように、特別なソフトウェアの導入をできるだけ不要とすること。具体的には、ウェブブラウザだけで参加できることが望ましい。
3)オープンソースソフトウェアを活用して、構築と運用のコストを抑えること。
4)参加者は、産学の異なる組織に属しているため、ネットワーク通信は業界標準プロトコルで行い、かつ各組織のファイアーウォールを越えての通信を実現する。したがって、プラットフォームのすべての通信をHTTPプロトコルで実現すること。
5)コミュニティ形成のためにはメンバー相互の信頼関係を醸成できることが重要である。その前提として、メンバーの認証が必要であると考え、プラットフォームへのアクセスはアカウント登録制とする。
ユーザの識別には、ユニーク性が保証されることと、連絡をとることが容易であることからメイルアドレスを用いることにした。ただし、メイルアドレスが陽に公開されてしまうことは避けるべきなので、プラットフォームの表示上のユーザの識別にはハンドル名を使用することとした。このメンバー認証の機能は計算系、検索系に共通する機能として実現した。
水科学研究に関連する計算プログラムを研究者のネットワークコミュニティで利用しあえる環境を実現するにあたって重要な点は、つぎのとおりである。
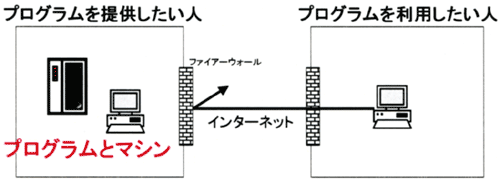
1)計算プログラムの実行環境を提供する研究者のコンピュータと、計算プログラムを利用したい研究者のコンピュータを、それぞれが所属する組織のファイアーウォールを越えてつなぐこと。図3-1に示すように、一般的に異なる組織間にはファイアーウォール(NAT環境も含む)が存在し、相互のコンピュータが直接通信することは困難である。
2)計算プログラムの実行環境を提供する研究者のコンピュータの安全性(ネットワークセキュリティ)を確保すること。
3)計算プログラムの実行環境を提供するにあたっての準備が簡便であること。
図3-1
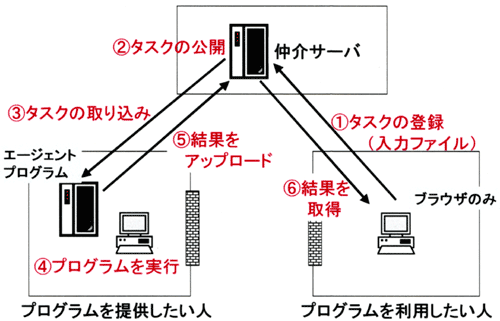
以上の要件を満たすために、図3-2に示すようにインターネット上にどこからでも自由にアクセスできるサーバ(仲介サーバ)を設置し、これを仲介役として機能させるアプローチをとった。
計算プログラムを利用したいユーザは、タスク(入力ファイル一式とプログラムの起動に関するパラメータ)を仲介サーバに登録する。(図3-2(1))この仲介サーバへの登録操作は一般のウェブブラウザで行う。仲介サーバは登録されたタスクを公開状態におく。(図3-2(2))一方の計算プログラムを実行するコンピュータは、仲介サーバに登録されているタスクを問い合わせる。問い合わせは計算プログラムの名前が検索キーとなる。もし、該当するタスクが登録されていれば、仲介サーバはそのタスク(入力ファイル一式とパラメータ)を返す。(図3-2(3))この入力ファイル一式とパラメータに基づいて計算プログラムを起動し所定の計算を実行する。(図3-2(4))計算が終了すると、その出力ファイルを仲介サーバにアップロードする。(図3-2(5))仲介サーバは、アップロードされた出力ファイルをはじめのタスク登録と結びつけて保管する。タスクを登録したユーザは、仲介サーバに問い合わせることによりタスクの結果(出力ファイル)を閲覧・ダウンロードする。(図3-2(6))
図3-2
タスクを登録しその結果を受け取るコンピュータと、タスクを取り込み実行するコンピュータは、いずれも仲介サーバに対してHTTPで接続するので、一般的なファイアーウォールを通過することができる。以上の処理の流れを繰り返すことによって、異なる組織に所属する研究者のコンピュータ同士が連携して計算の依頼と実行と結果の返送・取得を行うことができる。
計算プログラムを実行するコンピュータ側における一連の処理、タスクの問い合わせと取得(図3-2(3))、計算プログラムの実行(図3-2(4))、計算結果のアップロード(図3-2(5))は、自動化するべきであるので、そのためのプログラム「エージェントプログラム」を開発した。エージェントプログラム(以下、エージェント)の位置づけを図3-3に示す。エージェントは、仲介サーバからタスク(入力ファイルとパラメータ)をダウンロードすると、計算プログラム実行のための一時的ディレクトリ(ワークディレクトリ)を動的に作成し、このワークディレクトリ内に仲介サーバからダウンロードした入力ファイルを配置したのち、タスクに指定されたパラメータに基づいて所定の計算プログラムを起動する。計算プログラムの実行が終了したことを検出すると、ワークディレクトリ内のファイル(入力ファイル、出力ファイル)を仲介サーバにアップロードする。
|