|
5. 配船の自動作成
5.1 小型モデルの評価
5.1.1 モデルの概要
自動配船アルゴリズムの傾向を見るため、Table.1及びTable.2の小型モデルを対象に自動配船アルゴリズムを試適用した。なお、これらの設定は実際の輸送システムを参考としているが、内容は架空のものである(港湾配置についてはFig. 8を 参照)。
| Table.1 |
Port Specification of Mini Model
(5 ports, 3 items) |
| port name |
loading/unloading time zone |
number of berth |
item name (abbreviation) |
tank size [ton] |
increase rate [ton/day] |
| Muroran |
from 06 to 18 |
1 |
tar (TAR) |
1,800 |
+ 60 |
| creosote (CO) |
1,600 |
- 40 |
| Tahara |
from 06 to 18 |
1 |
creosote (CO) |
1,800 |
- 60 |
| black oil (BO) |
1,800 |
- 50 |
| Nagoya |
from 06 to 18 |
1 |
tar (TAR) |
2,000 |
+ 90 |
| Sakaide |
from 06 to 18 |
1 |
creosote (CO) |
3,000 |
+ 100 |
| Tobata |
available all day |
2 |
tar (TAR) |
4,500 |
- 150 |
| black oil (BO) |
1,500 |
+ 50 |
|
| Table.2 |
Tanker Specification of Mini Model
(2 tankers) |
| tanker id |
DWT |
number of hold |
speed [knot] |
| ballast |
full load |
| 0 |
1,200 |
5 |
12-9
(depend on setting) |
value of left column minus 1 |
| 1 |
1,100 |
5 |
value of tanker id0 minus 1 |
value of left column minus 1 |
|
5.1.2 遺伝子データベースのみを用いた配船計算
ヒューリスティックデータベースを用いず、遺伝子データベースのみをもとに配船を行った結果例を次に示す。なお、ship 0は空船速力9knot、ship 1は空船速力8knotと遅い仕様としており、輸送条件を厳しくして計算した。また、3.3.2における評価関数中の定数として、幾つかの値を試行した結果収束性が良くなる値としてCtは1.5を、Ciは4.5を用いた。
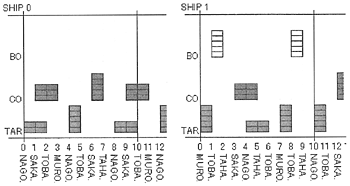
| Fig. 3 |
Tanker Allocation Summary
(Small Model without H-DB) |
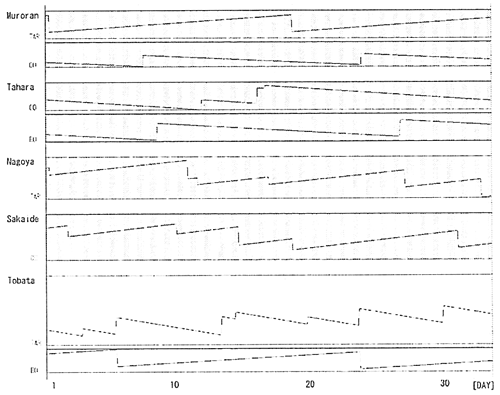
Fig. 4 Tank Level History (Small Model without H-DB)
Fig. 3はタンカーの配船内容のうち、各船が港間で積載する品目をまとめたものである。横軸には寄港する港名を順番に記載し、縦軸には品目毎に何個のホールドを占めていたかを記載する。
例えばship 0は、当初、名古屋港に行ってタールを2ホールド積み、次に坂出港へ行ってクレオソートを3ホールド積み(混載及び複数港積み)、次に戸畑港へ行ってタールを2ホールド揚げ、次に室蘭港へ行ってクレオソートを3ホールド揚げ(複数港揚げ)、更に名古屋港まで空船航海を行う配船である。
Fig. 4は陸上側タンクの在庫履歴を示したものである。横軸には時間を、縦軸は各タンクの在庫量を示す。傾きが正のタンクは当該品種を生産するタンクであり、傾きが負のタンクは当該品種を消費するタンクである。また、灰色の縦縞の部分は、荷役制限時間帯であることを示す。
どのタンクも、輸送開始時点よりも1月間の輸送終了時点の方が、タンクがオーバーフローもしくはドライアウトするまでの時間に余裕があるようになっている。安全余裕が増しており、妥当な配船であるといえる。
5.1.3 ヒューリスティクスデータベースを併用した配船計算
最も基本的な配船要素である遺伝子データベースのみを使うのではなく、3.3.1で述べた人間のヒューリスティクスを染色体の発生情報として併用することで、自動配船を効率化出来る可能性がある。そこで、以下の2種類のヒューリスティクスを導入した。
(1)「坂出港→室蘭港→戸畑港」
坂出港でクレオソートを満載し、次に室蘭港で全て揚げた上でタールを満載し、最後に戸畑港で全て揚げる。この配船は、室蘭港で揚げた直後に積むため輸送効率がよい。
(2)「坂出港→田原港→名古屋港→戸畑港」
坂出港でクレオソートを満載し、次に田原港で全て揚げ、名古屋まで空船航海を行った上でタールを満載し、最後に戸畑港で全て揚げる。この輸送は田原港−名古屋港間が近距離であるため輸送効率が良い。
上記をヒューリスティクスデータベースに加えた上で配船を行った結果例を以下に示す。各パラメータ値は5.1.2と同条件とした。
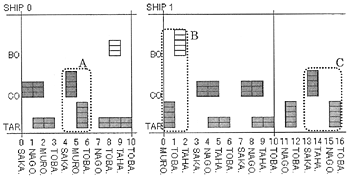
| Fig. 5 |
Tanker Allocation Summary
(Small Model with H-DB) |
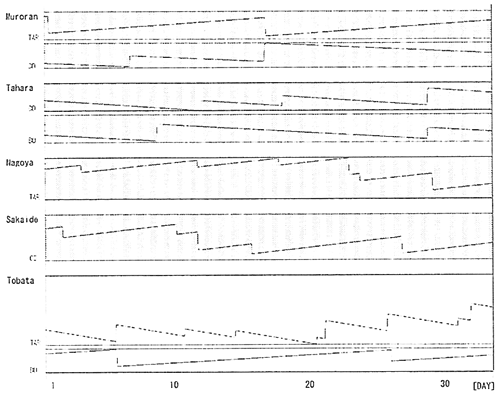
Fig. 6 Tank Level History (Small Model with H-DB)
Fig. 5の枠A及び枠Cの配船はヒューリスティクスデータベースから取得したものと考えられる。また、枠Bの配船は遺伝子データベースから生成した効率の良い配船であり、Fig. 3でも同様に生成されている。これは3.3.1(2)(3)「過去に生成した事例」の登録候補となる。
Fig. 6を見ると、輸送が成功裏に行われているだけではなく、どのタンクも輸送開始時点よりも1月間の輸送終了時点の方が、タンクがオーバーフローもしくはドライアウトするまでの期間に余裕が出るようになっており、安全余裕が増していることが分かる。
なお、上記例ではヒューリスティクスデータベースのあるなしで、両者の配船内容に顕著な優劣の差は認められない。
5.1.4 ヒューリスティクスデータベースの導入効果
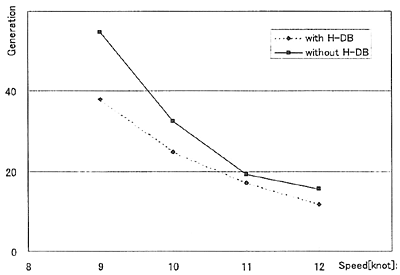
ヒューリスティクスデータベース導入の効果を見るため、当該データベースのある場合とない場合の輸送実施可能な解(オーバーフローもドライアウトも起こさずに輸送が可能な配船案)を最初に見つけるまでの世代交代数を調べる。併せて輸送の困難度に対する影響を観察するため、複数の船速に対する上記値の推移をプロットしたものがFig. 7である。
Fig. 7 Effect of Heuristic Data Base (Small Model)
グラフ中の各値は100回試行を行って得られた平均値である。それぞれの試行ではl00個からなる染色体プールを用いた。なお、船速が8knot以下の場合はヒューリスティクスデータベースの有無に関わらず、輸送を実施可能な解を得ることが出来なかった。
上図より、いずれの船速でもヒューリスティクスデータベースを用いた方が、用いない場合よりも少ない世代交代で輸送実施可能解を得られることが分かる。また、船速が小さい方が、すなわち、輸送が困難な条件下の方が導入の効果が大きい。これは、輸送が困難であるほど効率的な配船のみから配船計画を構成する必要があるため、効率的配船例から構成されるヒューリスティクスデータベースの効果が大きいからであるからと考えられる。
実船社を例に取った大型モデルを扱った場合でも、実用的な世代交代数内で解を見つけることが出来るかが問題である。
|