|
4. 分析対象データ及び説明変数の設定
ウラジオストックにあるAsia Pacific Maritime Information and Advisory Services(APMIAS)を通じて、Asia Pacific Computerized Information System(APCIS)に収録されているデータから2002年1月1日から2003年8月31日までの32121ケース及び2003年9月1日から2003年12月4日までの4985ケースを入手した。表1にそのデータの一部および説明変数として設定した項目を示す。定性的な変数である“IACSorNO”、“Ship Type”、“Detentionの有無”に対しては数量化した変数をその次の列に与えてある。例えばIACSがyesである場合は数値1をそうでない場合は数値0を割り当てると云う様な方式で数量化した変数を作成してある。
説明変数としての項目は、過去のPSC委員会の会合において議論され提案された各種の方式(表2)で使用された項目を 参照して表3に示すように選んだ。
重回帰分析については、予備解析として2003年9月1目から10月8日までの約1ヶ月間の1872ケースについて実施してみた結果、判別分析に比較して良好な結果が得られなかったので、本解析を実施するまでには到らなかった。
2002年1月1目〜2003年8月31日までの32121ケースのデータに対して判別分析を適用した。分析は拘留の有るグループと無いグループを正しく判別することを目標とした。ステップワイズ法により分析した結果、線型判別関数が(3)式の様に求まった。ただし、投入の打ち切りF値は4.0と設定して求めた。
Z = -0.909 + 0.053・V4 + 0.040・V8 - 0.341・V9 + 0.023・V11 + 0.388・V20 + 0.009・V21 ・・・(3)
ここで、線型判別関数を構成する変数として残ったものは以下のものであった。括弧の中の数値は表1の第1番目のデータが与える変数の数値である。
| 変数 |
(数値の一例) |
| V4: Ship flag(detention rate): % |
(3.12) |
| V8: Class(detention rate): % |
(4.09) |
| V9: IACS or NO(Yes=1, No=0) |
(1) |
| V11: Ship age: year |
(8) |
| V20: Number of detentions during last 4 inspections:回 |
(0) |
| V21: Number of deficiencies during last 4 inspections: 個 |
(2) |
|
第一番目のデータの場合、線型判別式によるZの値は-0.719となる。
なお、それぞれの変数のF値の大きい順に並べると以下のようになっている。F値が大きいほどZ値(判別の判断)への寄与が大きいと考えられる。
| 変数 |
(F値):(標準偏回帰係数) |
| V4: Ship flag(detention rate):% |
(304.2):(0.409) |
| V11: Ship age:year |
(130.8):(0.190) |
| V20: Number of detentions during last 4 inspections:回 |
(115.9):(0.210) |
| V8: Class(detention rate):% |
(49.3):(0.274) |
| V21: Number of deficiencies during last 4 inspections |
(39.4):(0.123) |
| V9: IACS or NO:(Yes=1, No=0) |
(11.6):(-0.115) |
|
この式の線型判別関数では説明変数が6個となっており、(3)式の様に比較的簡単な判別式となっている。
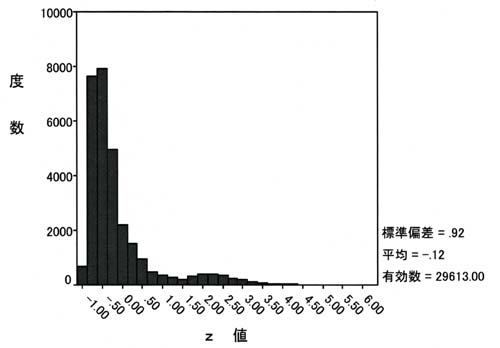
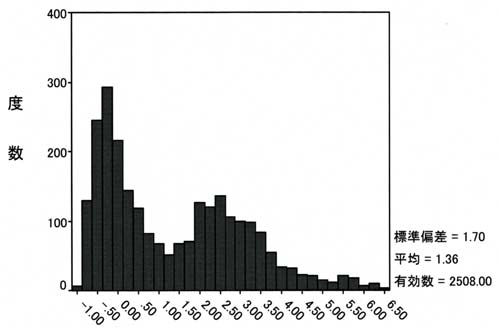
分析の結果得られた判別関数((3)式)による判別得点(Z値)毎の度数分布を示すと、図1、図2のようになる。
図1 グループ1(拘留なし)の度数分布
図2 グループ2(拘留有り)の度数分布
(3)式として得られた線型判別式を元に多変量解析ソフトSPSSでは表4に示す判別結果を与えている。SPSSでは全データをグループ分けする際に正答率を最大にする判定基準を用いている。今の場合、判別得点Zが2.28より大の場合に拘留有りと判定する基準となっている。
図1で見ると、Z=2.25以下の部分に本来グループ1に属するケースがほとんど属しており、このグループに対しては正しく判別している。一方、本来グループ2に属すケースのZ値の分布を示したのが図2である。この分布を見るとZ=2.25以下、つまりグループ1と判別されてしまう割合が半数以上の多数あることがわかる。
表4 SPSSによる(拘留の有無)の判別分析結果
| |
Detention
Yes=2, No=1 |
予測グループ番号 |
合計 |
| 1 |
2 |
|
| 元のデータ |
度数 |
1 |
28301 |
1312 |
29613 |
| 2 |
1703 |
805 |
2508 |
| |
% |
1 |
95.6 |
4.4 |
100.0 |
| 2 |
67.9 |
32.1 |
100.0 |
|
| a 元のグループ化されたケースのうち90.6%個が正しく分類されました。 |
我々の着目は拘留の可能性のある船舶をいかに効率よく捕捉するかにある。多変量解析ソフトSPSSにより得られる基準をそのまま用いてグループ2と判別された船舶のみを検査すると、全船舶の6%を検査するだけで良いのだが、拘留有りの可能性のある船舶の32%しか捕捉できないという結果になる。
本来グループ2(拘留あり)に属するデータを正しくグループ2と判断するためには、判断基準であるZ値を小さくしZ=-1.0まで下げれば良い事が図2からわかる。しかし判断基準をZ=-1.0にしてしまうと、図1から本来グループ1(拘留なし)に属するデータも全てグループ2(拘留あり)と判断してしまうことになる。
できるだけ、グループ2に属するデータを正しく判断し、なおかつ全体の正答率もそれ程下げない判断基準を求めることが問題となってくる。
|