|
3.2 NN Recursive Prediction Method
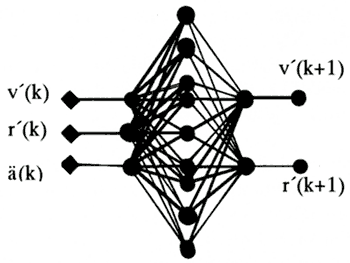
It has been proved that a three layers NN structure can fit any arbitrary non-linear function [5]. In the present paper, the prediction method is based on a NN Recursive Model (NNRM), which consists of three layers: one input layer (3 nodes), one hidden layer (20 nodes) and one output layer (2 nodes), as shown in Fig.3. Within every node, there is a sigmoid function operating on the inputs to the node and producing output, as shown following:
The input to sigmoid can vary from -∞ to +∞, but the output is constrained within 0 and 1.
Fig.3 Neural network structure.
We choose v', r' and ä at time k as input data and v', r' at time k+1 as output data. It should be noted that the time t' is non-dimensionalized by the time non-dimensionalized coefficient:
where, L is the barge train length.
3.3 Description of NNRM's Training Work
As discussed in Section 3.2, the NN model with the 3×20×2 structure plays a role of fitting such a function:
[v (k+1); r (k+1)]=Funame[v(k), r(k), δ(k)] (7)
This 'Funame' gives a kind of mapping from [v' (k); r' (k); ä (k)] at the prior time to [v' (k+1); r' (k+1)] at the next time, and is identical to what the Eq. (4) expresses.
4. COMPARISON OF SIMULATION WITH MEASURED DATA
4.1 Neural Network Training
A neural network is an implicit and indirect mathematical mechanism whereby an arbitrary nonlinear relationship from n-dimensional space to another m-dimensional space can be expressed. The most important for well applying NN is its successful training using original data sets.
The next step is to train the neural network in order to emphasize and mix some of the stimuli, practically ignore others, and consider the rest in moderation so to generate the desired output. The back-propagation technique is a very powerful method to adjust the weights of the neural network.
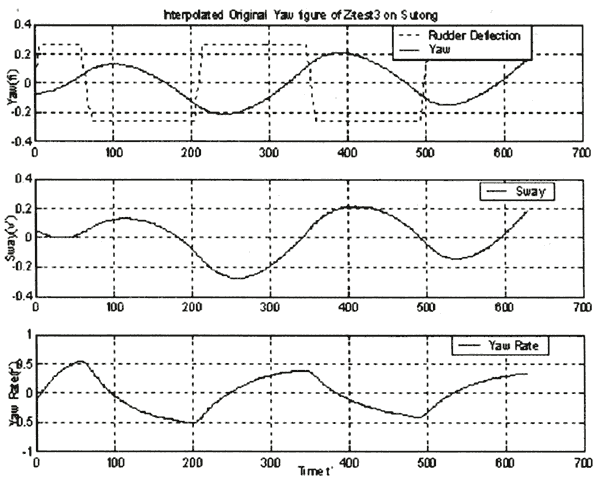
The original data of Test3 is shown by the following charts:
Fig.4 The original measured motion data.
The sample frequency is 0.1 Hertz, so the sampled time interval is 10 seconds. To satisfy the discrete NNRM, the data interpolation is applied to produce values per second and filter is used to get smooth values.
It should be noted that the bad condition may appear if the NNRM is over trained. From our experience, 500 iterations are enough to decrease the mean square error to 1 .e-6, and it is recommended to restart the training work if the error curve is not satisfactory after 500 iterations.
What's more, the choice of training algorithm is very important for error convergence. Different training functions behave different convergence abilities. After many attempts, Bayesian regularization was proved to have better performance than others. Foresee and Hagan (1997) gave some suggestion on neural network training using Livenberg-Marquardt algorithm, which minimizes a linear combination of square errors and weights and also modifies the linear combination so that the resulting network has good generalization qualities at the end of training.
|