|
第4章 データベースの構築
4.1 データベースの構成
収集したインベントリー情報及び観測データより、昨年度の基本設計に従ってデータベースを構築した。
本業務で構築するデータベースは大きくは以下の2種類に分かれる。
(1)観測インベントリー情報のデータベース:
第3章で属性付加したインベントリー情報のデータベースで、移動型観測ではクルーズ別、係留型観測では1地点・1期毎に観測情報を記録したもの
(2)観測データのデータベース:
観測データ(実データ)を収録したファイル
また、昨年度整理した観測・研究プロジェクトに関する情報(日本海で行われた代表的な観測・研究プロジェクト別に観測情報をまとめたもの)は、インベントリー情報とは別に整理し、html形式で閲覧できるようにした。
データベースの最上位には図4.1に示すようなhtml形式のインデックスファイルを設け、各データベースにアクセスしやすいようにした。
データベースの構成を図4.2に示す。
図4.1 データベースのインデックス画面
図4.2 データベースの構成
4.2.1 データの様式
第3章で作成したインベントリー情報ファイルは、前述のとおり入力、管理しやすいExcel形式で作成している。
しかし、このままではアプリケーションへの依存度が強いため、本データベースへの収録形式としては、これをカンマ区切りのテキストファイル(CSV形式)で保存するものとした。
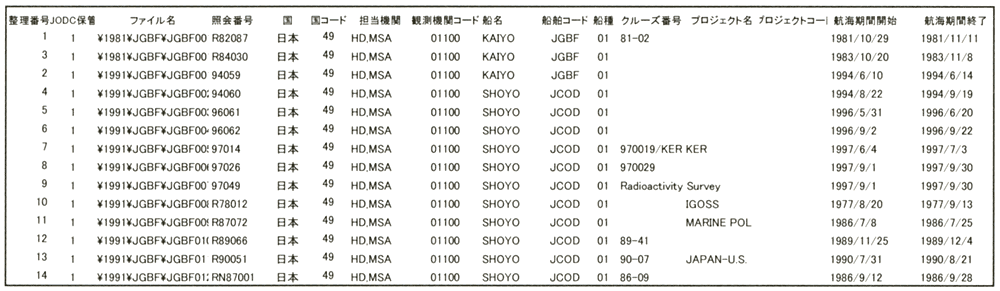
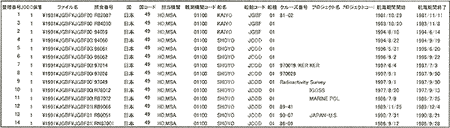
インベントリー情報のデータ構成の一例を図4.3に示す。
インベントリー情報は、1レコードに1クルーズの情報を記録しており、項目は表3.4に従っている。但し、図4.3(1)のように左端には整理番号を記載し、また後述する観測データとの関連付け情報としてJODCにおけるデータの有無、ファイル名を付加することとした。
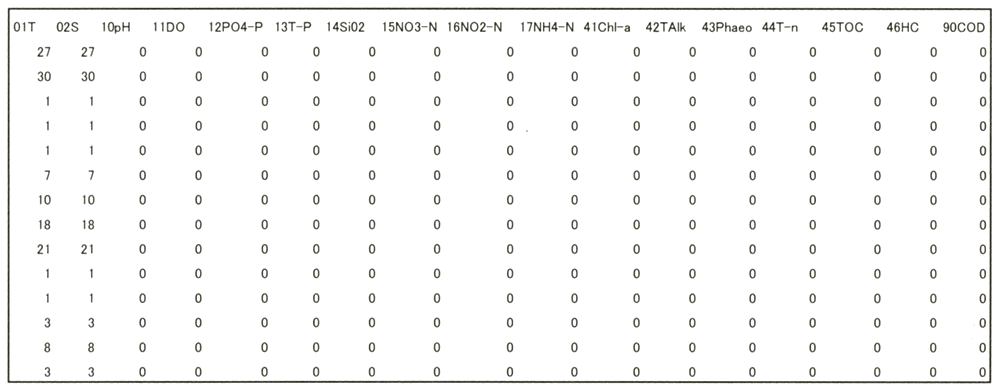
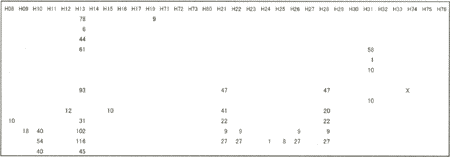
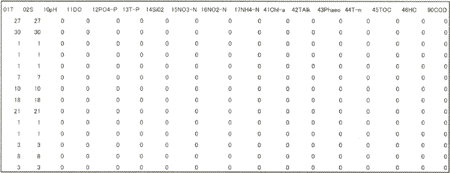
また、データ項目については、CSRから入力した情報では表4.3(2)のようなタイプコード別(CSRのタイプコード;付表−4(1)(2))に測点数を記録しているが、観測データから抽出した情報では表4.3(3)のようなタイプコード別(FETIのタイプコード;付表−4(3))に記録している。
このように、CSR等に基づいて入力した場合と、観測データから抽出した場合では記載項目がかなり異なるため、データベースのチェック・修正などの便宜を考慮して両者は別々のファイルで保管する。
図4.3(1)インベントリー情報ファイルの構成例
|
(拡大画面:48KB)
|
 |
|
図4.3
|
(2)インベントリー情報ファイルの構成例
(データ数;CSR型コード)
|
|
(拡大画面:14KB)
|
 |
|
図4.3
|
(3)インベントリー情報ファイルの構成例(データ数;FETI型) |
|
(拡大画面:24KB)
|
 |
インベントリー情報から、そのクルーズで観測したデータを検索しやすくするため、観測インベントリーと観測データの間に次のような関連を持たせることとした。
まず、本業務では日本海の環境変動について検討するという目的を踏まえ、観測データベースは後述するように年代別\船舶別\クルーズ別の階層構造とした。
次いで、インベントリー情報の各レコードと全観測データを照合し、船舶コードが一致し、かつインベントリー情報の観測期間内のデータを含むファイルを検出した。この結果、該当データが検出された場合は「JODC保管の有無」に「1」、検出されない場合は「0」を記入するとともに、前者の場合はファイル名(図4.2における\Data以下のフルパス;例えば\Data\19yy\aaaa\aaaa001.dat)を記入した。
これより、観測データベースのディレクトリを辿れば、容易にデータを検出できる。
また、インベントリー情報を条件付き検索できるよう、図4.4に示す検索用プログラムを準備した。
図4.4 インベントリー情報の検索用画面
|